Horizons your
model can't reason with. Yet.
10,000+ domain specialists. 100+ disciplines. 30+ regions. We produce the reasoning, voice, and evaluation datasets that frontier AI teams can't build in-house.
Post-training performance is bounded by data quality. We raise the bound.
As models move from pattern matching to multi-step reasoning, the training data bar rises with them. You need experts who can design novel problems, evaluate chain-of-thought logic, and produce domain-specific datasets across languages and disciplines. Scraping the web won't get you there. Neither will crowd platforms.
Quanta Labs has immediate access to 10,000+ active, vetted domain specialists across 100+ fields. We match the right experts to your project in days, not months. Every task runs through calibration, multi-layer QA, and structured review before delivery.
From reasoning puzzles to dialect-level voice annotation.
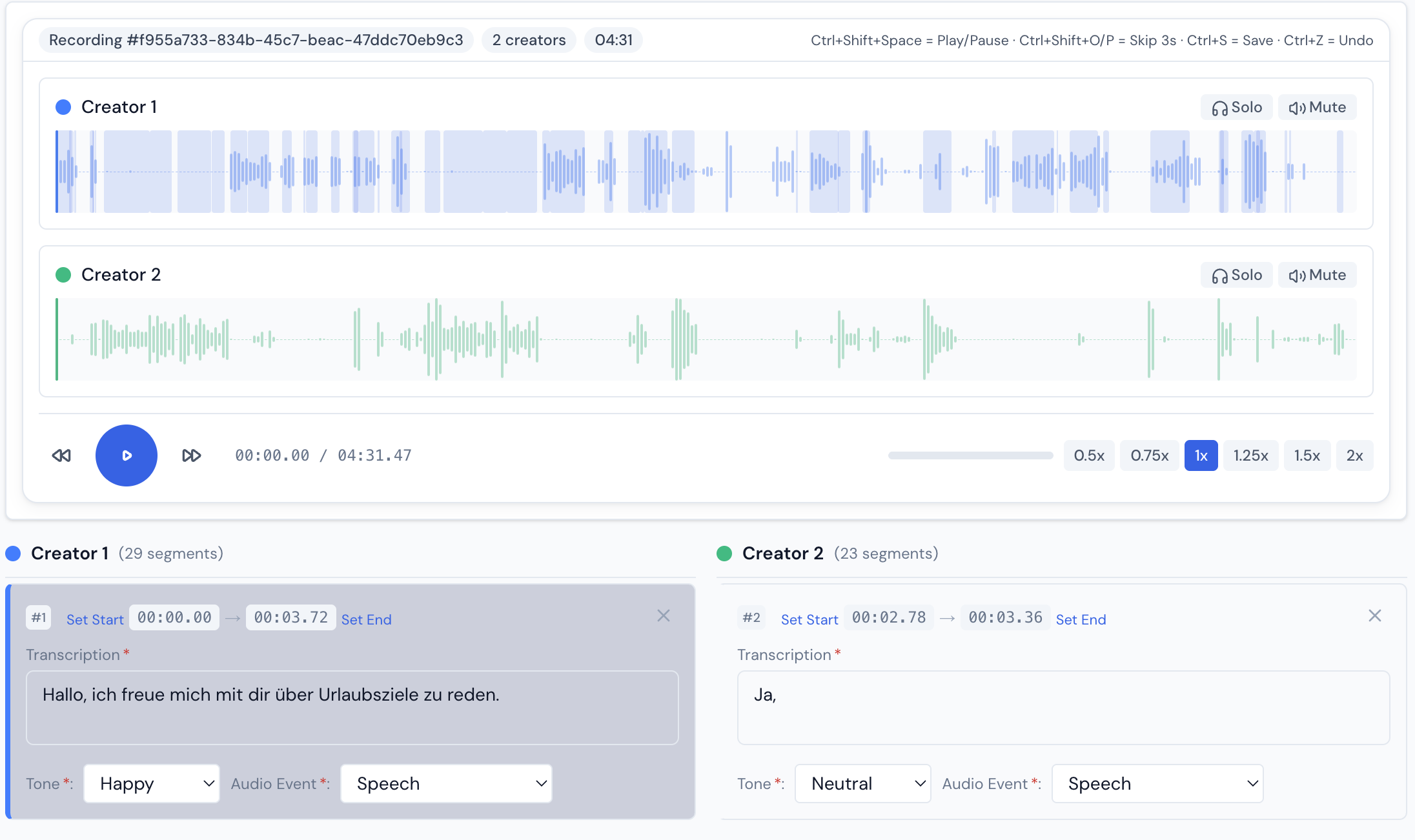
Voice annotation with native-speaker transcription and sentiment tagging

ARC-AGI evaluation tasks designed by domain specialists
We don't scale bodies. We scale expertise.
Expert-first, not crowd-first
Every task is matched to specialists with verified domain expertise. Mathematicians for logic. Linguists for dialect work. Engineers for technical reasoning. Not a crowd hoping for the right answer.
Every datapoint is defensible
Full lineage from expert selection to final delivery. When your model gets audited, your regulator asks questions, or your evaluation fails, you can trace exactly how every label was produced and by whom.
Live in days
Our specialist network is already active and vetted. We scope, match, and start delivery within days. No months-long onboarding. No cold-start problem.
What your pipeline receives.
Reasoning Datasets
Novel logic puzzles, multi-step reasoning chains, and domain-specific problem scenarios. Expert-designed with unique rule systems to push model capability, not repeat what’s already in the training set.
Model Evaluation
Gold sets, regression benchmarks, adversarial probes, and failure-mode test suites. Built to find what your model gets wrong, across safety, accuracy, helpfulness, and policy compliance.
Human Feedback Data
Preference rankings, rubric-based scoring, multi-turn conversation feedback, and expert adjudication. Structured for direct integration into reward model training pipelines.
Voice & Multilingual Data
Native-speaker audio and text data across 45+ languages. Dialect-specific recordings, diverse speaker profiles, and culturally grounded datasets. Deep European coverage from Portuguese to Bulgarian.
Your next benchmark starts with a conversation.
Let's talk.
Reasoning data, model evaluation, voice datasets, or something we haven't seen before. We'll scope a pilot and activate domain specialists within days.
No commitment. Custom-scoped to your pipeline.